In the last post, we used flask to deploy our ML model. Today, we will be exploring a different framework to achieve the same – Falcon. Falcon is pretty simple to work with. Lets get coding :
Install Falcon
Load your virtual environment and do
pip install falcon
I used python 2.7 and falcon==1.1.0. This will get falcon installed.
Bare bones Example
The code consists if 2 files – app.py [contains app structure and end points] while functionality.py contains the code to support the functionality.
imports falcon package and create a basic application; access hello_world object from functionality.py and create a end point ‘hi’ where when data is sent via POST request, appropriate function of hello_world object is invoked.
Here codes does following : create a class hello_world with on_post() – it takes a request and response object. Consume the request object and set the attributes of response object. Lets get the code running.
Show time :
Prerequisite: You need gunicorn server. load you virtual environment and do
pip install gunicorn
I used python 2.7 and gunicorn==19.6.0
Run the following steps in terminal:
Use cd to path where app.py is saved.
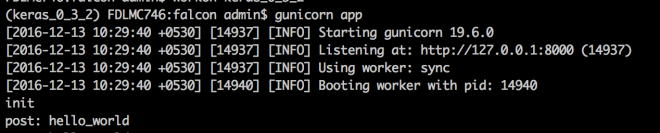
gunicorn app
This should get the gunicorn server up and running :
gunicorn up and running
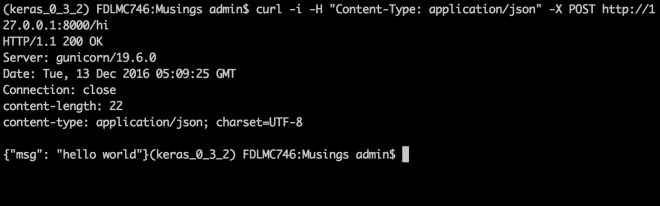
Lets hit the server with a POST request. Open another terminal and type in:
curl -i -H "Content-Type: application/json" -X POST http://127.0.0.1:8000/hi
On the client terminal you should see 200 ok followed by a json containing our hello world message.
Command and response on Client side
On the server terminal you should see our print statement in on_post().
Server Side
Congrats, your first application in falcon is up and working !
I am told falcon is light weight. I am not an expert on this topic, here are a couple of links if you wish to take a deep dive into Flask vs Falcon: Python web framworks benchmarking, reddit thread, hacker news,slant.
<!– Deploy ML model via Falcon: –>
Flask is a lightweight Python web framework to create microservices. Wanna read more ? I am a ML guy, and this sounds complex 😦 Rather than reading lets code a simple one quickly !
Install Flask
pip install flask
I used python 2.7 and Flask==0.11.1
Bare bones Example
Open a editor and copy paste code from my git repo
from flask import Flask
app = Flask(__name__)
@app.route('/1') # path to resource on server
def index_1(): # action to take
return "Hello_world 1"
@app.route('/2')
def index_2():
return "Hello_world 2"
if __name__ == '__main__':
app.run(debug=True)
To run this:
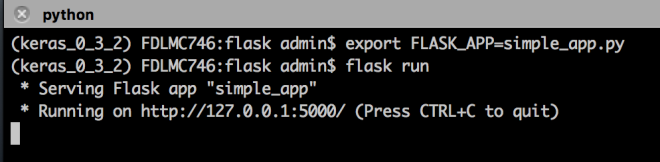
Save it as simple_app.py
Install Flask in your virtual environment [pip install Flask]
Open terminal, go to the directory where app.py is saved. Run following two commands
If you see the code carefully it says – we have 2 resources with relative URIs as ‘/1’ and ‘/2’. Lets access them. Go to browser and type http://127.0.0.1:5000/1
This should fire index_1() function and output be like
Like wise http://127.0.0.1:5000/2 should work. This is a simple flask application. (Oh yeah ! this sounds easy, lets go ahead)
REST (in peace)
There are a couple of terms that are part and parcel on micro services. Lets quickly understand something about them.
API : Application Program Interface – set of routines, protocols, and tools for building software applications.
API Endpoint :It’s one end of a communication channel, so often this would be represented as the URL of a server or service. In our example “http://127.0.0.1:5000/1”
REST :underlying architectural principle of the web. Read these awesome post and this and this to understand the same
In nutshell, you need to have – GET, POST, PUT, DELETE.
Lets add this to our code. To see this in action, run the server (like previously), go to terminal and type
curl -i http://localhost:5000/tasks
OR
curl -i -X GET http://localhost:5000/tasks
Both commands will give same output:
GET request
Your server terminal will show “200” (success) for both requests.
200 – success
RESTful App
Lets add other parts of RESTful to out code. Here it is. To see this in action, run the server (like previously), go to terminal and type:
Get All tasks:
curl -i http://localhost:5000/tasks/
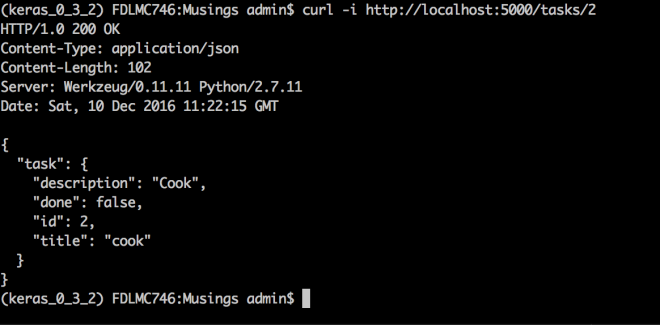
Get a specific task:
curl -i http://localhost:5000/tasks/2
Get task with id=2
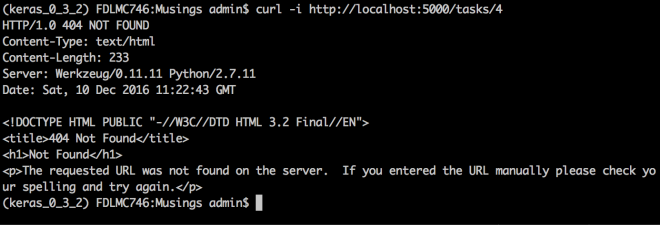
Since there is task with id=4, try this:
curl -i http://localhost:5000/tasks/4
Error. Task with id=4 does not exists
Add a task:
curl -i -H "Content-Type: application/json" -X POST -d '{"title":"Read a book"}' http://localhost:5000/tasks/
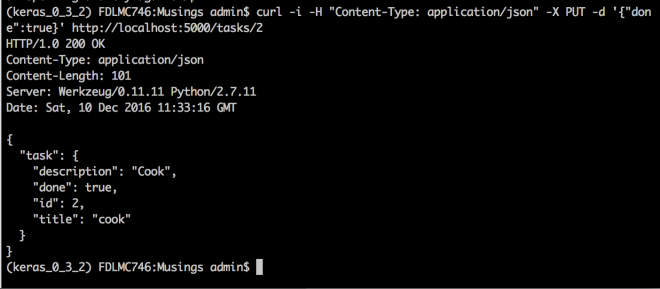
Update a specific task:
curl -i -H "Content-Type: application/json"-X PUT -d '{"done":true}' http://localhost:5000/tasks/2
Task 2’s status is updated [‘done’:true]
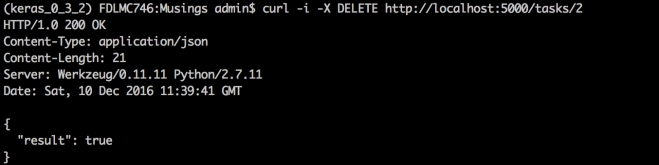
Delete a specific task:
curl -i -X DELETE http://localhost:5000/tasks/2
task with id=2 successfully deleted.
Source: Large part of the code comes from Miguel Grinberg awesome post.
ML app
Its all great until now, what about the core issue – ML model as microservice ? Here we go:
from flask import Flask, jsonify, request, abort
import pickle
import numpy as np
app = Flask(__name__)
model_file_path = "./../models/final_model.pkl"
model = None
def get_prediction(X):
X_i = X.reshape(1, 2)
print "X_i.shape"
print X_i.shape#load the model if not already done
global model
if model == None:
model = pickle.load(open(model_file_path, 'rb'))#make prediction and return the same
prediction = model.predict(X_i)[0]
return prediction
@app.route('/predict', methods=['POST'])
def predict():
if not request.json or not 'X1' in request.json or not 'X2' in request.json:
abort(404)
X1 = request.json['X1']
X2 = request.json['X2']
X1_ = np.float64(X1)
X2_ = np.float64(X2)
X = np.array([X1_, X2_])
prediction = get_prediction(X)
return jsonify({'prediction':prediction})
if __name__ == '__main__':
app.run(debug=True)
To run this code, get the server up and running and then fire the command below from another terminal.
Complete code is here.It has lot of print statements. You should see these statements printing the relevant stuff on the server terminal.
Model Prediction
Lets understand some key aspects of this code. Here, predict() handles any POST request coming on /predict on the server. We extract the payload – components of input vector – these cannot be sent from client as numpy arrays. These components come in as unicode strings. Hence, we transform them explicitly into numpy.float64 and then make a numpy array on the server side. There is an elegant way to do it, which we will see in short while.
Once we have the payload in right format, we invoke the function – get_prediction(). Its main job is load the model into memory if not already loaded, and fire the model on input for getting the prediction.
We have a model that is up and running as service. Now you can go ahead and add more functionality like resetting the model, training the model if not already trained, and lot more.
[If you face any issue with the code, pls open a bug request on Github. All the above 4 files are available here. ]
I have often heard Data scientist/ML people asking for “I have ML model doing well on, how do I deploy it in production environment ?” Recently I have been exploring the same, so sharing some of my findings and ways to the same. Here focus will be on deployment and not developing a model – hence for simplicity we will assume we have a simple pre-trainied, fine tuned scikit model ready to be deployed.
This is a 3 part series. We will see how to deploy a ML model as a microservice. We will see 3 ways of doing the same:
Flask
Falcon
Jupyter notebook as service (Wow!)
Microservice – what and why ?
Microserivce is an architecture pattern. It can best be thought as being completely opposite of Monolithic architecture (problems). The central idea is to break the system/applications into small chunks(services) based on functionality. Each chunk does a specicifc job and does only that. These services talk to each other using HTTP/REST (synchronous or asynchronous). Want to take a deep dive ? I suggest read this and this.
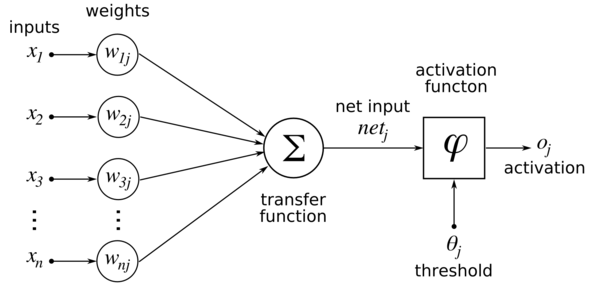
The activation function of a node defines the output of that node given an input or set of inputs. A standard computer chip/boolean circuit can be seen as a digital network of activation functions that can be “ON” (1) or “OFF” (0), depending on input.
Fig 1 : Activation Function
In short:
What: Transform / squash the input. Mapping from set of inputs to output.
Why: Transforms the input(s) to a different space/domain where it may be easily separable [9]. Input to the input layer in a neural net is usually linear transformations – but real world data and real problems are usually nonlinear . To make the incoming data non-linear we use a non-linear mapping called Activation function.
Different Types of activation functions
Following are the popular activation functions used frequently while designing DeepNets:
Softmax : If the output(s) of the DeepNet will be or need to be interpreted as posterior probabilities for a categorical target variable, the output(s) should follow the axioms of probability theory :
Each output ;
Sum of all outputs .
Softmax does exactly this.
Let the net input to output unit be , [, ] where is the number of categories. Then the softmax output, , of output unit is given by:
[Its trivial to verify that ‘s as defined above satisfies the axioms of probability theory.]
Sigmoid : It takes a real-valued number and “squashes” it into range [0,1]. In particular, large negative numbers become 0 and large positive numbers become 1. Sigmoid function can also be interpretated as the firing rate of a neuron: from not firing at all (0) to fully-saturated firing at an assumed maximum frequency (1).
Sigmoid is defined as :
At one point of time, sigmoid was the defacto activation function. They have fallen out of favour because:
(-) Sigmoids tend to saturate & kill the gradients. When the neuron’s activation saturates at either tail – 0 or 1, the gradient at these regions is almost zero. Recall that during backpropagation, this (local) gradient will be multiplied to the gradient of this gate’s output for the whole objective. Therefore, if the local gradient is very small, it will effectively “kill” the gradient and almost no signal will flow through the neuron to its weights and recursively all the way to its data. Additionally, one must pay extra caution when initializing the weights of sigmoid neurons to prevent saturation. For example, if the initial weights are too large then most neurons would become saturated and the network will barely learn.
(-) Sigmoid outputs are not zero-centered. This is undesirable since neurons in later layers of processing in a Neural Network would receive non zero-centered data. This influences the dynamics during gradient descent, because if the data coming into a neuron is always positive (e.g. element wise in ), then the gradient on the weights during back-propagation will become either all be positive, or all negative (depending on the gradient of the whole expression ). This can introduce undesirable zig-zagging dynamics in the gradient updates for the weights. However, notice that once these gradients are added up across a batch of data, the final update for the weights can have variable signs, somewhat mitigating this issue. Therefore, this is an inconvenience but it has less severe consequences compared to the saturated activation problem above.
ReLU : Stands for Rectified Linear Unit andis based on rectifier function; = . A node/unit in a DeepNet using a Relu is called Rectified Linear Unit.Formally: ReLU introduces non linearity to the network. Advantages:
As compared to other activation functions such as sigmoid hyperbolic tangent, ReLU is super efficient to compute; without any significant compromisation to generalisation accuracy.
ReLU greatly accelerates (e.g. a factor of 6 in Krizhevsky et al.) the convergence of stochastic gradient descent compared to the sigmoid/tanh functions. It is argued that this is due to its linear, non-saturating form.
Sparse activation: For example, in a randomly initialized network, only about 50% of hidden units are activated (having a non-zero output).
Efficient gradient propagation: No vanishing gradient problem or exploding effect.
Softplus : . Often used as smooth approximation to the Relu.
Relu : Relu is based on rectifier function; = . A node/unit in a DeepNet using a Relu is called Rectified Linear Unit.
Mathematically: ReLU() = .
Advantages:
ReLU greatly accelerates (e.g. a factor of 6 in Krizhevsky et al.) the convergence of stochastic gradient descent compared to the sigmoid/tanh functions. It is argued that this is due to its linear, non-saturating form.
Think of any good machine learning system you have seen or read about recently – highly likely its based on Deep Learning. Its a word I am sure you have heard it, possibly even read a bit on it. If not, here is quick intro to it :
Humans have always been fascinated by the idea of building machines that can mimic human brain. Inspired by this idea, people introduced “artificial neural networks”(ANNs). ANNs are a family of models inspired by biological neural networks (the central nervous systems of animals, in particular the brain). Deep learning, is a set of powerful techniques for learning in neural networks.
Deep Learning was introduced in speech recognition problems in 2009. Since then they spread very rapidly across all areas of machine learning & AI. There multiple reasons for this rapid spread of deep learning among ML practitioners, chiefly being :
Auto Feature Extraction: In traditional ML systems based on SVMs, decision trees, Naive Bayes, etc features were hand picked by system designer. This required lot of careful study, domain knowledge and experimentation; this required intense time and effort on the part of data scientists. In contrast, deep learning facilitates “auto” extraction of important/useful features. These are learned directly from the data and need no manual engineering.
Better Features: The features DeepNets extract are often more complex and more relevant and more robust than hand-crafted features. This is because of the feature hierarchy possible in a deep net.
High Accuracies : Deep Nets are often able to achieve state-of-the-art results on data without expert knowledge on how to prepare features for that specific task.
Towards general AI: Owing to the use artificial neurons, it is also thought to somewhat resemble the way our brain works and researching into that direction seems to be a promising step towards “more intelligent” AI.
While DeepNets hold a lot of promise, designing good DeepNets is not an easy task. From the architecture of the network (FeedForward, CNN, LSTM, RNN etc) to various parameters of a DeepNet – each choice is super crucial as it has a huge bearing on the performance (both accuracy and efficiency) of the DeepNet. Of these myriad of choices, three important components any practitioner must choose carefully are : which Activation function, Loss/Objective Function and Optimiser to use ?
Given the large number of choices for each of these three components, the task of ML engineer doesn’t get any easier. In the coming posts we will take a deep dive into each of these three components. Our attempt will be to build a better understanding of various choices and understand the pros and cons of each of these nut & bolt.
From where does one begin to talk about data science ? Guess where every data scientist begins – Data !
What is data ? Data is nothing but facts that are generated by some process.
Let us see some examples.
Example 1 : A flight going from New Delhi to London. In this case, data could be a log file containing values recorded, by various sensors fitted in the plane, across the entire duration of flight. Or it could be what actions did the pilot take during the course of flight.
Example 2: A bunch of computer jobs are running on some 3rd party server like Amazon Web Services. In this case, Data could be – what all jobs ran with their respective Start and End time. Or it could be resources (such as RAM, processor) usage by various jobs.
As it might be clear from above examples, Data is collection of facts. So if you take a couple of pictures of your house, that too are facts about your house. So that too is Data. Here is simple 3 min video talking more about data.
So far so good. One might wonder as to why in last 3-4 years there is so buzz around data and data science ? You look at any organization, they either have created position(s) called “Data Scientist” or in the process of creating such a position(s). Lets look at some prominent reasons for this spurt:
Last decade has seen a revolution in computing devices in human life (ipad, mobile, laptops, smart watches, fitbits, GPS navigation deices and what not). Presence of these devices has produced human-computer interaction in never seen before ways, so be it be shopping online from amazon or social media like facebook and twitter. Further, in every office or factory there is more automation or atleast monitoring done via (if not by) computers. And these interactions combined with cheaper computing power has made it possible to collect, store and analyze data in ways never done before.
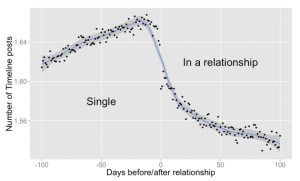
The central Idea behind Data sciences is find interesting patterns which are otherwise hard to find. What patterns ? could be as simple as “Can you predict the relationship status of a person from his facebook posts”. It seems we can ! Read More.
Courtsey: When You Fall in Love, This Is What Facebook Sees
Or as Dilbert found the key driving force behind his sales increase.
So then who is a Data Scientist ? A person who knows how to finding “interesting” patterns from data using a scientifically sound technique.
In next blog we gonna talk about life cycle involved in data sciences
Data Driven, Analytics, Big Data, Machine Learning are some of the buzz words one hears everywhere in today’s IT industry. This buzz is fueled by every organization trying using data to create a strategic advantage. Guess Edwards Deming summed it up beautifully when he said – “In God we trust. All others must bring data.”
Be it be mutibillion global firms like Apple or Nike or a small start-up in a corner of the world, or a Government Department designing next public policy, they are all driven by data and numbers. This fervor makes one believe that data is the new Oil ! Every day more and more data-driven systems are coming up trying to find those elusive insights that are crucial for a business. Google for “Data Science”, and it will throw an endless list of links on the web.
So why another blog on Data Science ? This blog is a small attempt to highlight/document some of my learnings, issues that I have come across during my journey in the world of data science. By no means this blog comes anywhere close to giving a guided tour to this beautiful and mystical world. At most this blog can be said to be an attempt to share the musings of a data scientist who is fascinated by a smoother pebble or a prettier shell than ordinary, whilst the great ocean of knowledge and data science lay all undiscovered before him. Hopefully, someone may find these musings helpful.
Disclaimer: The content in this blog represents the opinions and understanding of the Author. I have taken at most care to be as correct as possible. All data and information provided on this site is for informational purposes only. This is a personal weblog. The opinions expressed here represent my own and not those of my employer.

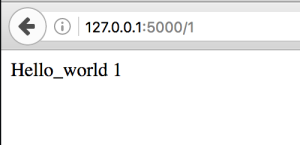 Like wise
Like wise 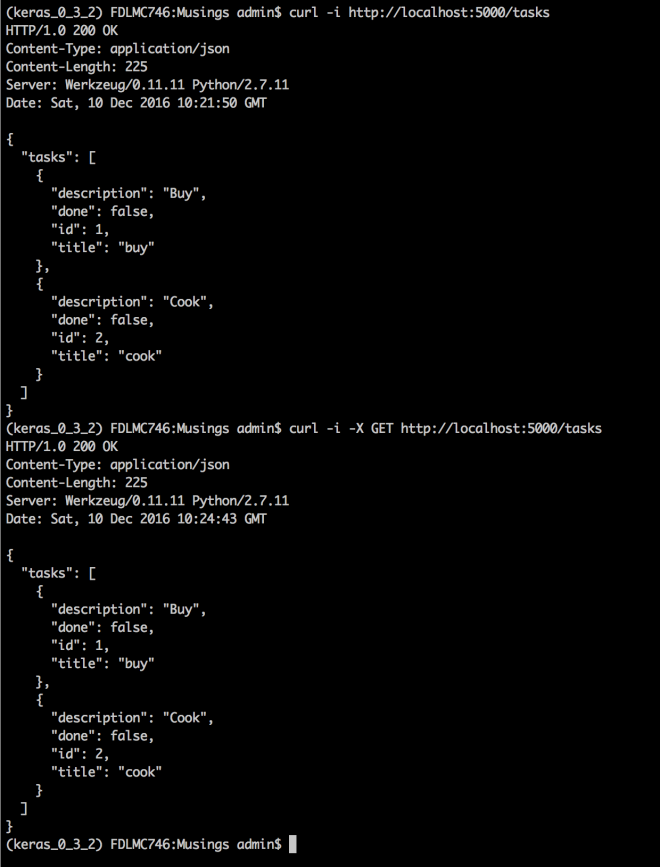



 but real world data and real problems are usually nonlinear . To make the incoming data non-linear we use a non-linear mapping called Activation function.
but real world data and real problems are usually nonlinear . To make the incoming data non-linear we use a non-linear mapping called Activation function. ;
;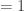 .
.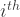 output unit be
output unit be 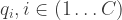 , [
, [ , ] where
, ] where  is the number of categories. Then the softmax output,
is the number of categories. Then the softmax output,  , of
, of 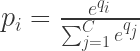
 ‘s as defined above satisfies the axioms of probability theory.]
‘s as defined above satisfies the axioms of probability theory.]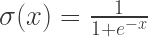
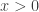 element wise in
element wise in  ), then the gradient on the weights during back-propagation will become either all be positive, or all negative (depending on the gradient of the whole expression
), then the gradient on the weights during back-propagation will become either all be positive, or all negative (depending on the gradient of the whole expression  ). This can introduce undesirable zig-zagging dynamics in the gradient updates for the weights. However, notice that once these gradients are added up across a batch of data, the final update for the weights can have variable signs, somewhat mitigating this issue. Therefore, this is an inconvenience but it has less severe consequences compared to the saturated activation problem above.
). This can introduce undesirable zig-zagging dynamics in the gradient updates for the weights. However, notice that once these gradients are added up across a batch of data, the final update for the weights can have variable signs, somewhat mitigating this issue. Therefore, this is an inconvenience but it has less severe consequences compared to the saturated activation problem above.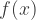 =
= 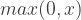 . A node/unit in a DeepNet using a Relu is called Rectified Linear Unit. Formally:
. A node/unit in a DeepNet using a Relu is called Rectified Linear Unit. Formally: 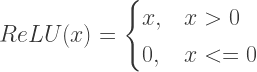 ReLU introduces non linearity to the network.
ReLU introduces non linearity to the network. 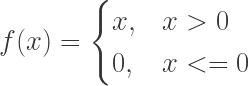
 . Often used as smooth approximation to the Relu.
. Often used as smooth approximation to the Relu. =
= 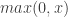 . A node/unit in a DeepNet using a Relu is called Rectified Linear Unit.
. A node/unit in a DeepNet using a Relu is called Rectified Linear Unit.  ) =
) =